
See How We Transform Data Into Story!
Our Work
Portfolio Showcase for Python Project
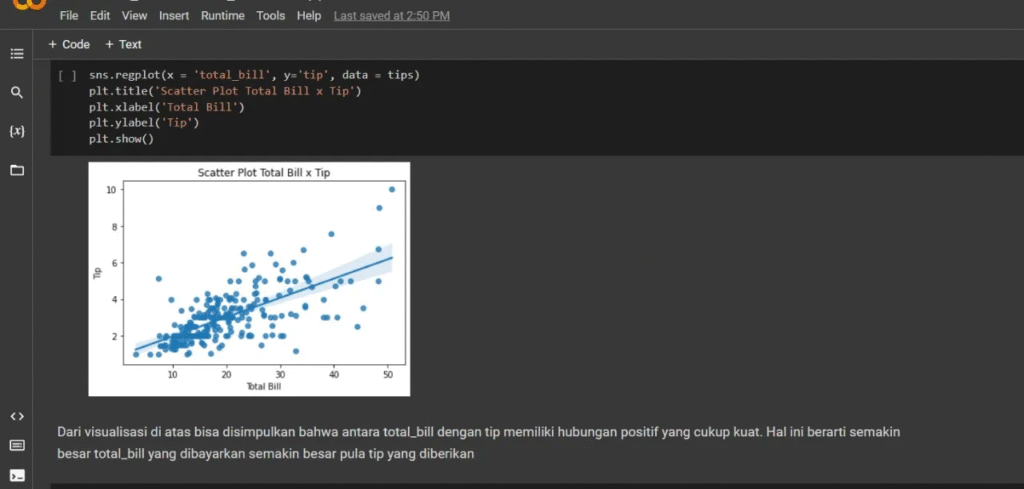
Exploratory Data Analysis
Kami menganalisis data untuk membuktikan bahwa ada hubungan positif yang kuat, semakin tinggi tagihan pelanggan, semakin besar tip yang diberikan. Ini menunjukkan bahwa strategi harga dapat langsung memengaruhi total pendapatan.
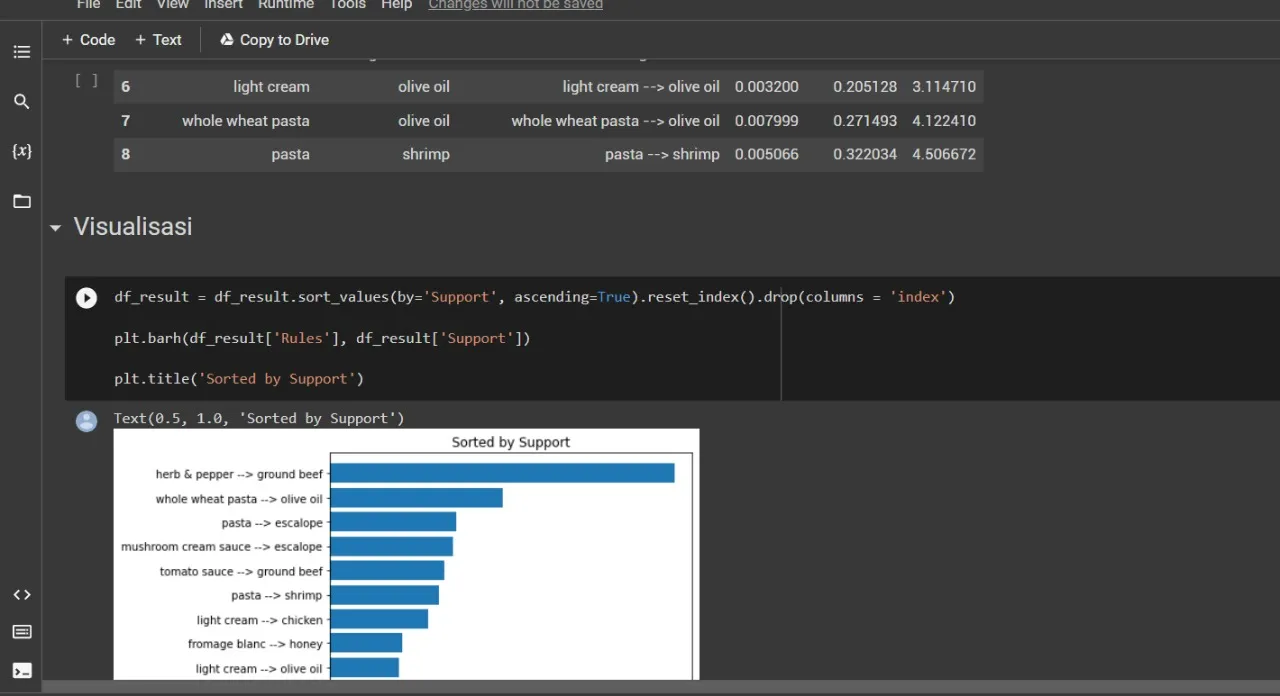
Buyer Data Analysis
Proyek ini mengimplementasikan konsep dari data mining dengan menggunakan algoritma apriori untuk mencari informasi yang dalam hal ini berupa pola pembelian barang oleh konsumen dengan memanfaatkan tumpukan data transaksi penjualan.
Classifications using Python
Mengolah data dengan beberapa metode seperti pre-processing, future selection, klasifikasi menggunakan 2 bahasa yaitu Python dan R
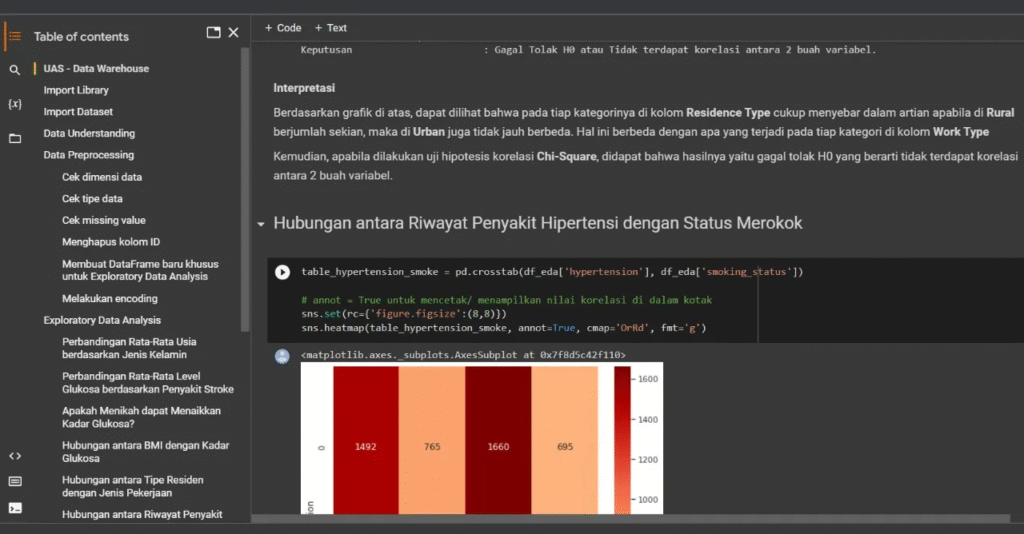
Analisis Faktor Risiko Kesehatan
berfokus pada pembersihan dan eksplorasi data kesehatan, menguji korelasi statistik antara faktor gaya hidup dan riwayat penyakit (termasuk status merokok dan hipertensi), serta mengidentifikasi variabel yang berpengaruh untuk persiapan pembangunan model prediksi yang akurat.
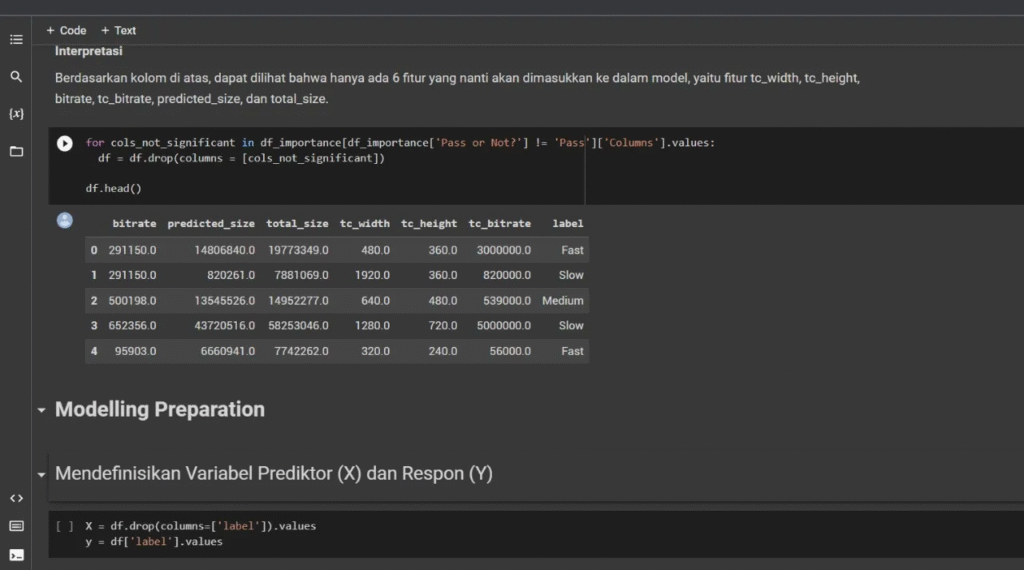
Prediksi Latensi Pemrosesan Video
Proyek ini berfokus pada pembangunan sistem untuk memprediksi waktu pemrosesan (latency) dalam konversi video digital. Kami menggunakan Python di Google Colab untuk melakukan pre-processing data video, menerapkan metodologi feature selection yang ketat, dan menguji berbagai model prediktif untuk menemukan model yang paling akurat.
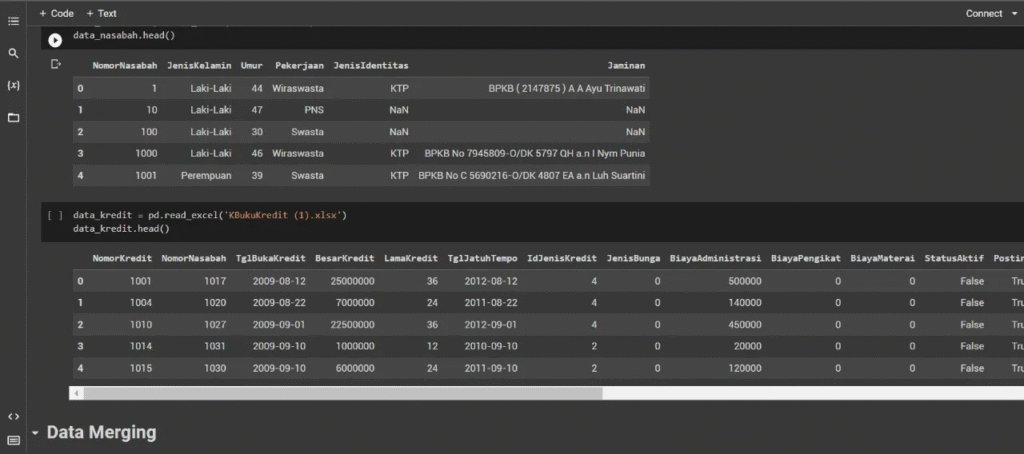
Sistem Klasifikasi Kelayakan Kredit
Proyek ini adalah solusi Data Mining menggunakan algoritma klasifikasi C4.5 dalam Python untuk menganalisis dan menggabungkan data historis nasabah dan riwayat kredit (termasuk kasus kredit macet). Tujuannya adalah membangun model prediksi yang kuat untuk secara otomatis menentukan kelayakan kredit nasabah baru.
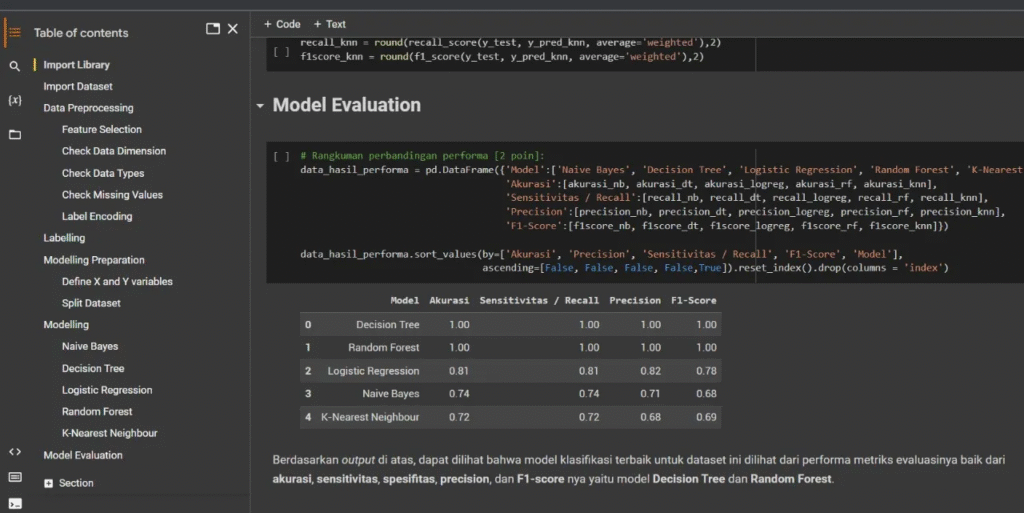
Klasifikasi Rating Menggunakan Ensemble Learning
Kami membangun dan mengevaluasi Model Machine Learning (terbaiknya Decision Tree dan Random Forest) menggunakan Python untuk memprediksi rating konten Netflix berdasarkan genre, rating IMDB, dan detail produksi. Model ini mencapai akurasi sempurna dalam klasifikasi rating.
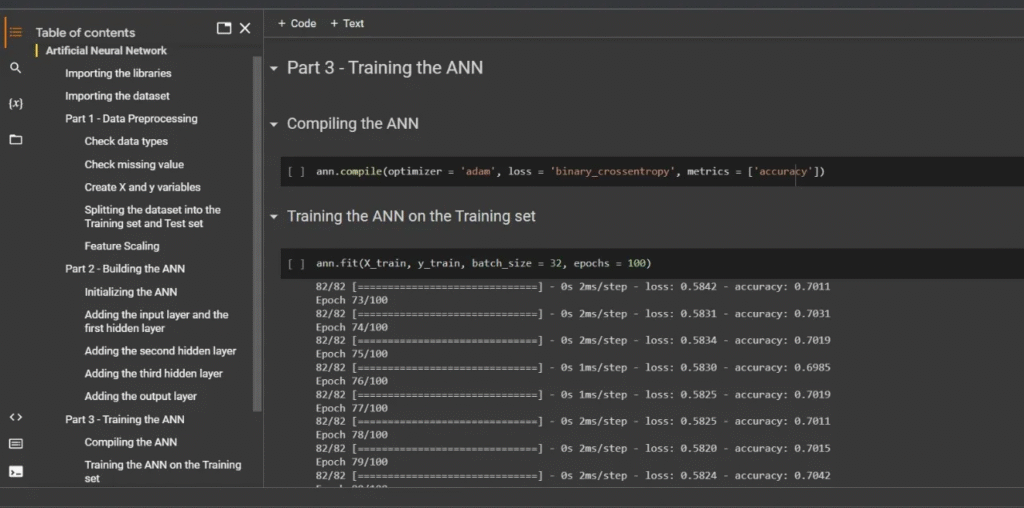
Deteksi Kualitas Air dengan Artificial Neural Network
Proyek ini menerapkan Artificial Neural Network (ANN) untuk mengatasi masalah klasifikasi yang kompleks, yaitu mendeteksi kualitas air (layak atau tidak layak konsumsi) dari data sampel CSV. Setelah melalui tahapan data preprocessing dan pembangunan struktur ANN yang berlapis (deep learning), model dilatih menggunakan optimizer Adam selama 100 epochs.
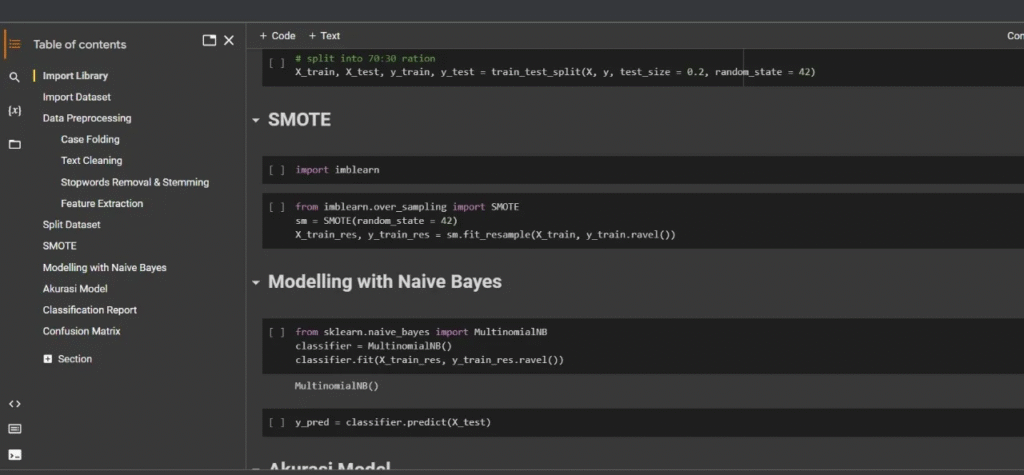
Analisis Sentimen dengan SMOTE & Naive Bayes
Proyek ini adalah implementasi Analisis Sentimen menggunakan algoritma Naive Bayes dalam Python. Untuk mengatasi masalah ketidakseimbangan data (misalnya, lebih banyak sentimen positif daripada negatif), kami menerapkan teknik SMOTE (Synthetic Minority Over-sampling Technique). Model yang dihasilkan mampu mengklasifikasikan sentimen (positif, negatif, atau netral) dari data teks dengan presisi yang ditingkatkan berkat penanganan data yang imbalanced secara efektif.
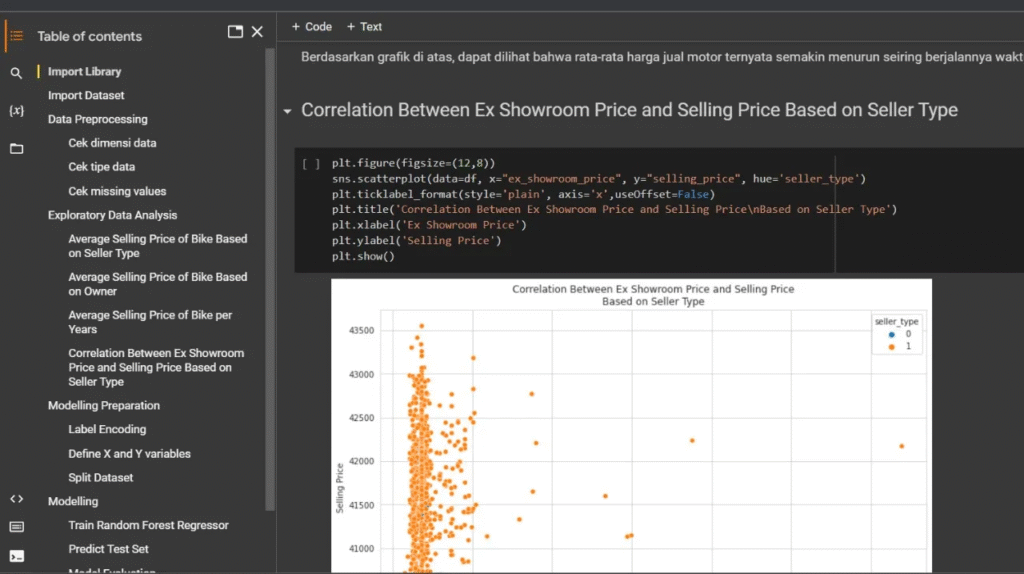
Prediksi Harga Motor dengan Random Forest
Proyek ini menggunakan Random Forest Regressor dalam Python untuk memprediksi harga jual motor bekas secara akurat. Kami melakukan data cleaning dan analisis korelasi harga jual terhadap faktor-faktor seperti harga awal dan jenis penjual untuk menghasilkan model prediksi harga yang optimal.

Analisis Sentimen Interaktif (Deployment Streamlit)
Proyek ini adalah pengembangan Aplikasi Web Streamlit menggunakan Python yang mampu melakukan Klasterisasi Analisis Sentimen secara real-time. Aplikasi ini menerapkan algoritma unsupervised learning K-Means untuk mengelompokkan teks input menjadi sentimen (Positif, Negatif, Netral) secara otomatis. Solusi ini memberikan platform interaktif dan user-friendly bagi klien untuk mendapatkan wawasan sentimen dari data teks instan.
Our Work
Portfolio Showcase for R Project
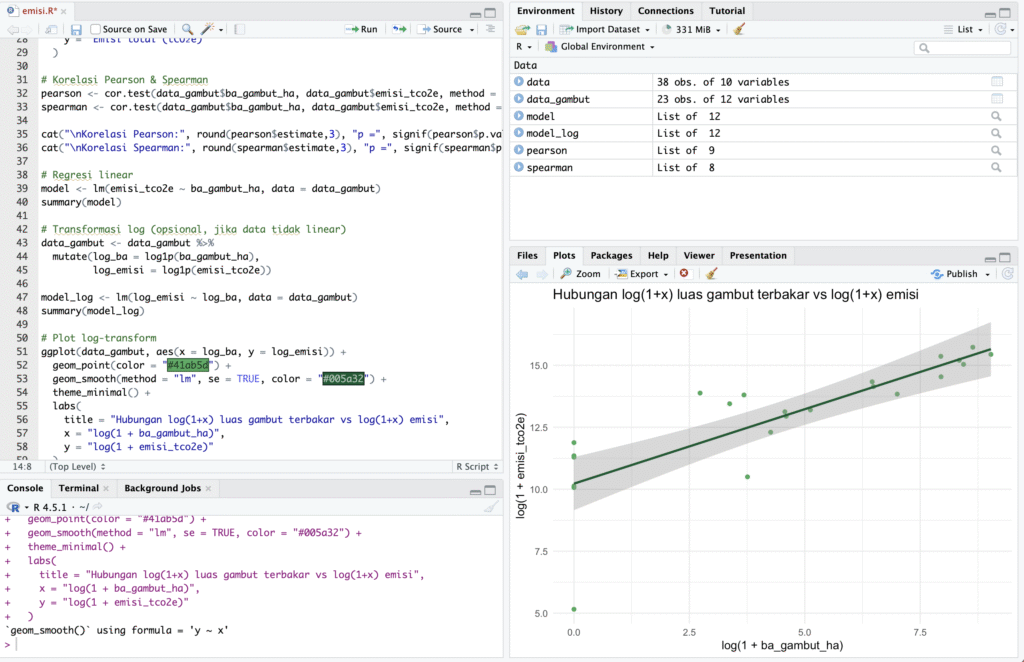
Hubungan Log-Linier Luas Gambut Terbakar Terhadap Emisi CO2
Proyek ini bertujuan untuk memodelkan hubungan antara luas gambut yang terbakar dan tingkat emisi dengan menggunakan uji korelasi Pearson/Spearman dan Regresi Linier setelah data variabel diubah ke bentuk logaritma. Hasilnya, yang ditampilkan dalam plot dengan garis regresi, mengkonfirmasi adanya hubungan positif yang signifikan antara luas lahan gambut terbakar dan emisi yang dihasilkan.
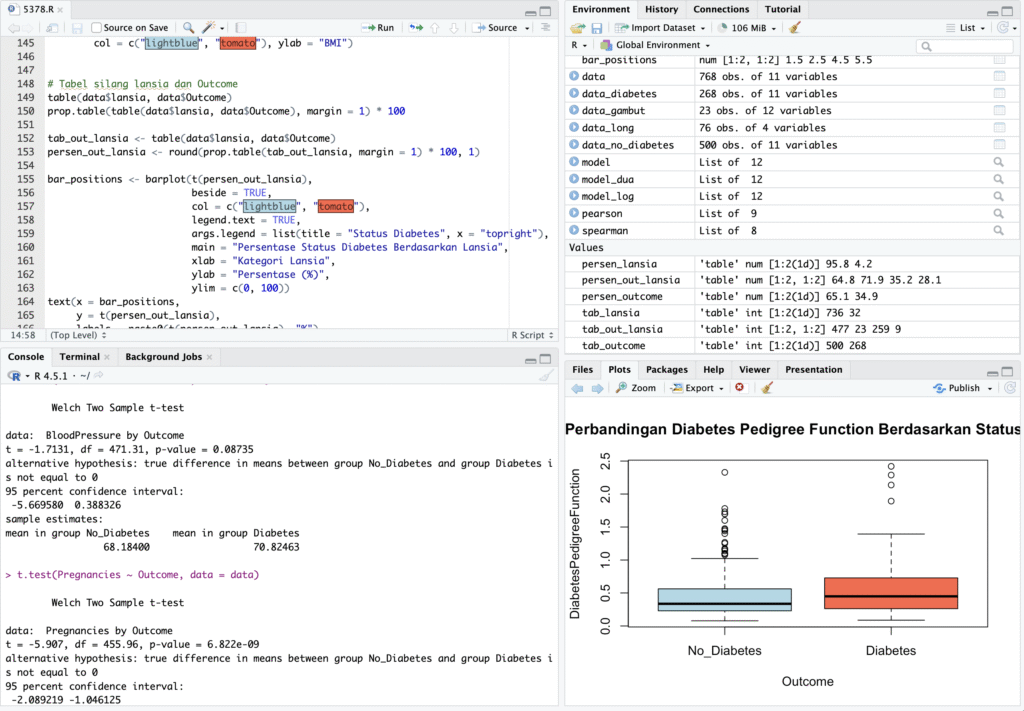
Perbandingan Rata-Rata Untuk Data Medis Kasus Diabetes
Proyek ini merupakan analisis data kesehatan terhadap 768 record untuk mengidentifikasi variabel-variabel yang secara signifikan memengaruhi status diabetes (variabel Outcome). Hasil utama menunjukkan bahwa tujuh dari sembilan variabel independen (termasuk Glucose, BMI, dan Age) memiliki perbedaan rata-rata yang signifikan pada kelompok pasien diabetes.
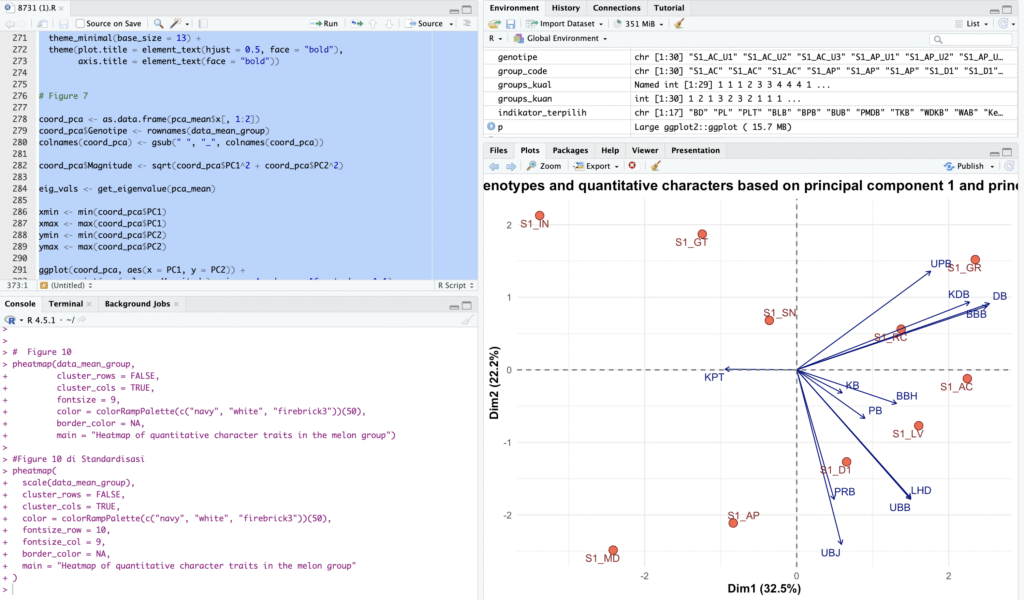
Analisis Multivariat dan Klasterisasi Genotipe Menggunakan PCA/MCA
Proyek ini menjalankan analisis multivariat komprehensif (Multiple Correspondence Analysis/MCA untuk data kualitatif dan Principal Component Analysis/PCA untuk data kuantitatif) yang dilanjutkan dengan Klasterisasi Hierarki untuk mengelompokkan genotipe menjadi empat kelompok, kemudian memvisualisasikan hasilnya secara ekstensif.
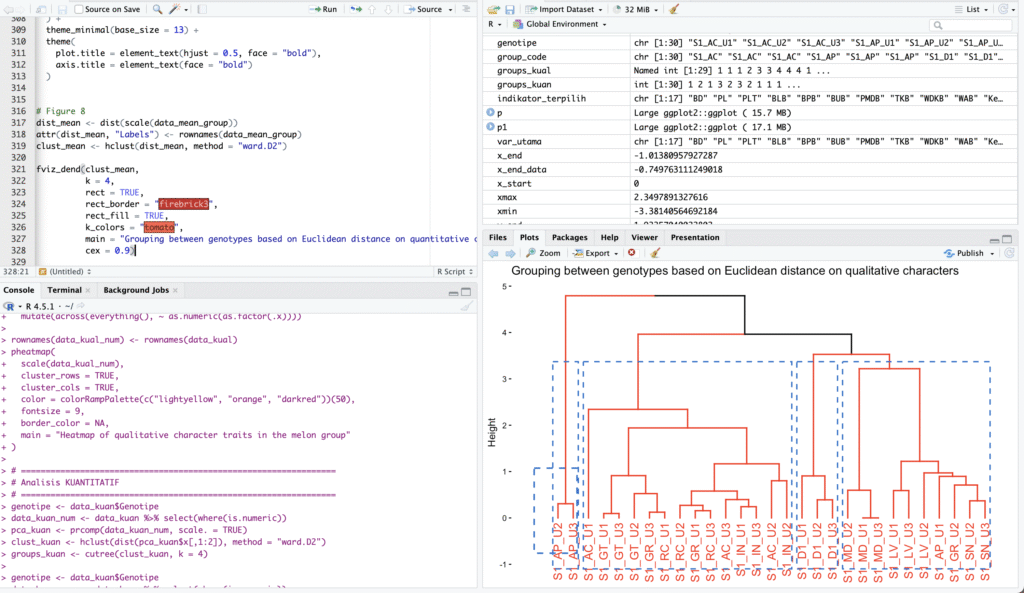
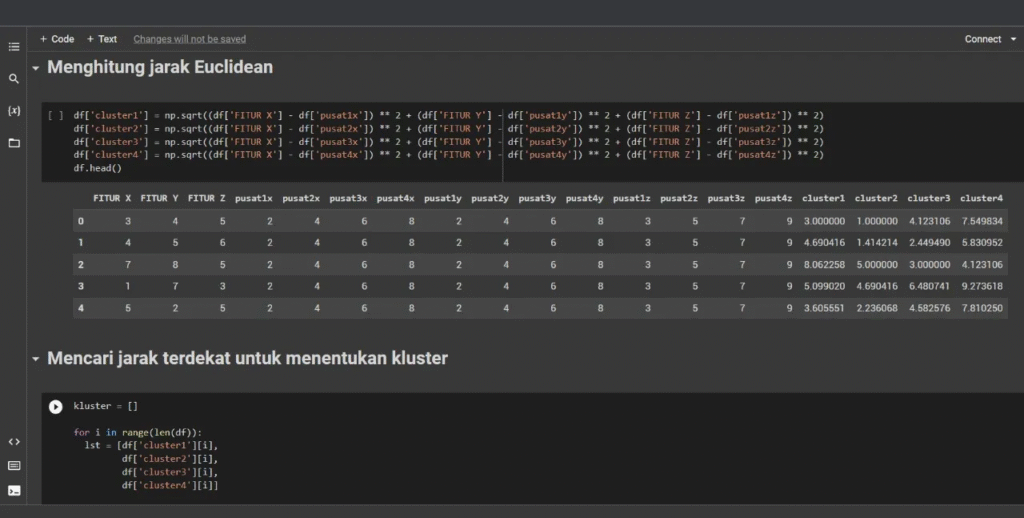
Pengelompokan Genotipe Berdasarkan Jarak Euclidean pada Karakter Kualitatif
Kode R ini menjalankan analisis multivariat komprehensif (Multiple Correspondence Analysis/MCA untuk data kualitatif dan Principal Component Analysis/PCA untuk data kuantitatif) yang dilanjutkan dengan Klasterisasi Hierarki untuk mengelompokkan genotipe menjadi empat kelompok, kemudian memvisualisasikan hasilnya secara ekstensif.
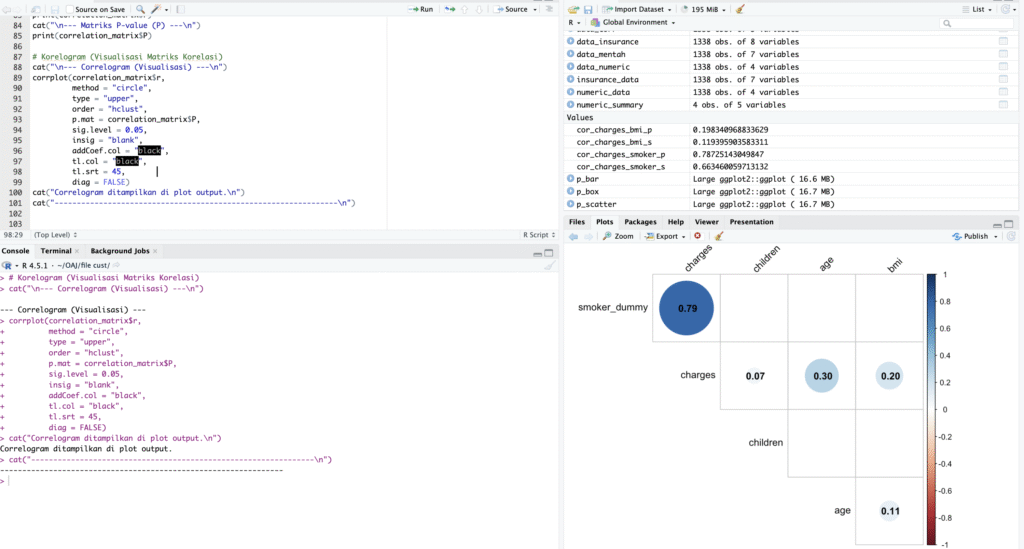
Visualisasi Data Correlogram dan Pengujian Koefisien Korelasi Pearson & Spearman
Proyek ini bertujuan untuk melakukan analisis data eksploratif guna mengidentifikasi dan mengukur kekuatan hubungan antara berbagai variabel demografi dan kesehatan terhadap Biaya Medis (Charges) dalam data asuransi. Melalui visualisasi data (Scatter Plot, Box Plot) dan perhitungan koefisien korelasi Pearson serta Spearman.
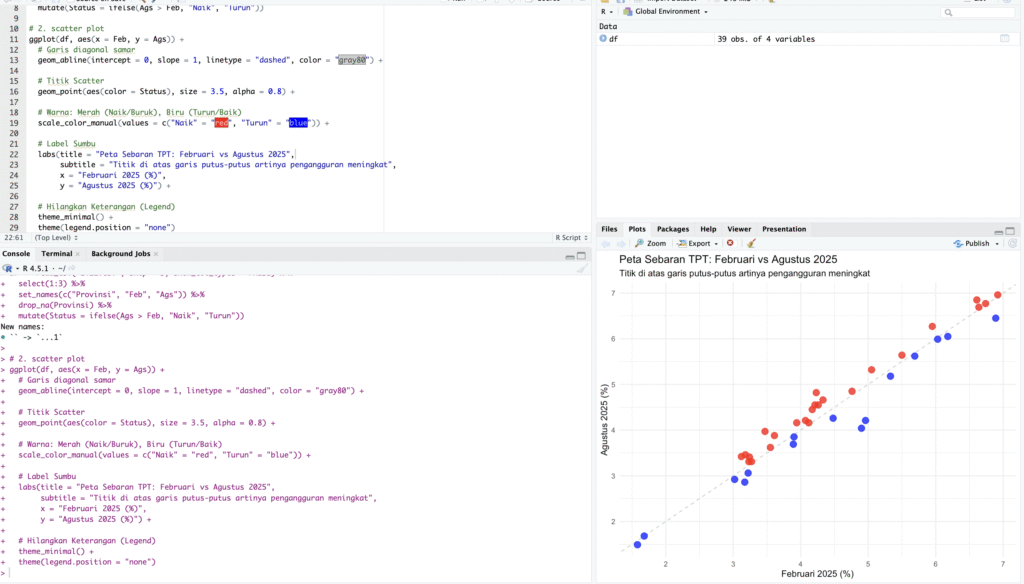
Visualisasi Data Correlogram dan Pengujian Koefisien Korelasi Pearson & Spearman
Proyek ini memvisualisasikan data Tingkat Pengangguran Terbuka (TPT) 38 provinsi melalui Scatter Plot Diagonal. Analisis menunjukkan polarisasi tren pasar kerja provinsi-provinsi dengan TPT tinggi seperti DKI Jakarta menunjukkan perbaikan (titik di bawah garis diagonal), sementara Jawa Barat dan Banten menghadapi kenaikan marginal (titik di atas garis).
Our Work
Portfolio Showcase for SEM SmartPLS Project
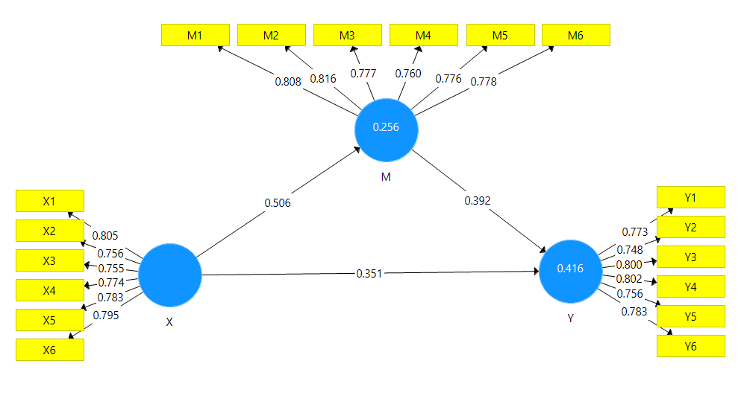
Pengaruh Financial Technology terhadap Inklusi Keuangan dan Peran Mediasi Literasi Keuangan
Proyek ini menganalisis hubungan sebab-akibat yang signifikan antara Financial Technology (FinTech), Literasi Keuangan, dan Inklusi Keuangan pada 200 responden. Hasilnya menunjukkan bahwa FinTech dan Literasi Keuangan secara bersama-sama mampu menjelaskan 41% tingkat Inklusi Keuangan. Semua hubungan yang diuji adalah positif dan signifikan, dan yang terpenting, Literasi Keuangan terbukti menjadi perantara penting yang memperkuat dampak FinTech dalam mendorong Inklusi Keuangan di masyarakat.
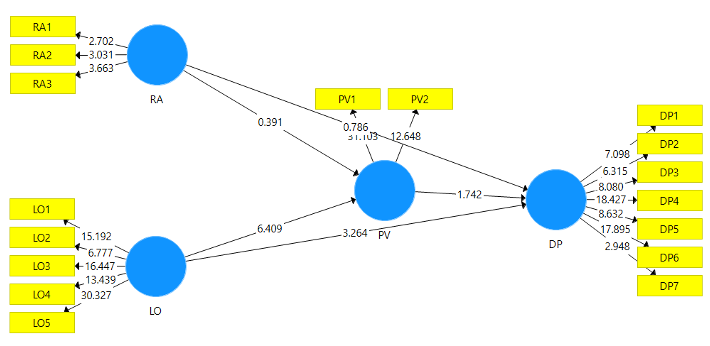
Pengaruh Local Ownership terhadap Decision Performance
Proyek analisis ini mengkonfirmasi bahwa Kepemilikan Lokal (Local Ownership) adalah faktor utama yang secara signifikan dan positif mendorong Kinerja Keputusan dan Nilai yang Dirasakan (Perceived Value). Meskipun diuji, faktor Sikap Risiko dan Nilai yang Dirasakan sendiri tidak terbukti secara signifikan memengaruhi Kinerja Keputusan. Model ini terbukti valid dan terpercaya, memberikan wawasan kunci mengenai pendorong kinerja
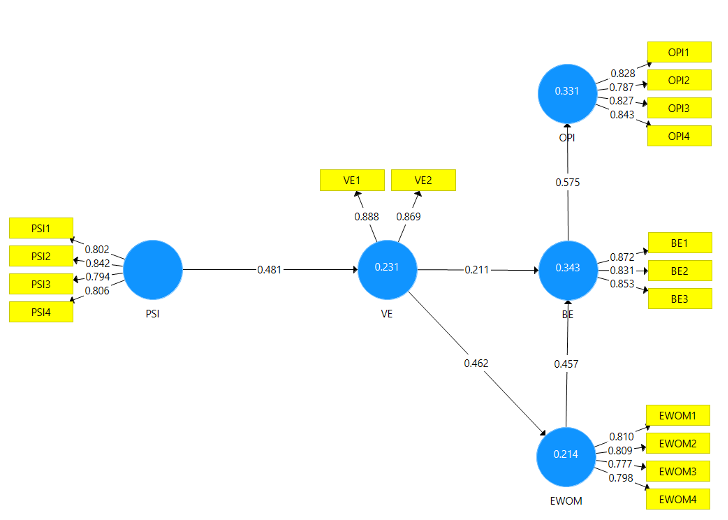
Model Mediasi Berantai Pengaruh Parasocial Interaction terhadap Online Purchase Intention
Proyek ini menganalisis model mediasi kompleks di mana Interaksi Parasosial (PSI), Ekspresi Viskarius (VE), dan Efek Bandwagon (BE) secara berantai memengaruhi Niat Pembelian Daring (OPI). Semua instrumen terbukti valid dan terpercaya. Hasilnya menunjukkan bahwa semua hubungan langsung dan semua jalur mediasi berantai yang diuji terbukti positif dan signifikan, menegaskan adanya pengaruh berlapis dari faktor-faktor sosial dan psikologis terhadap niat beli konsumen.
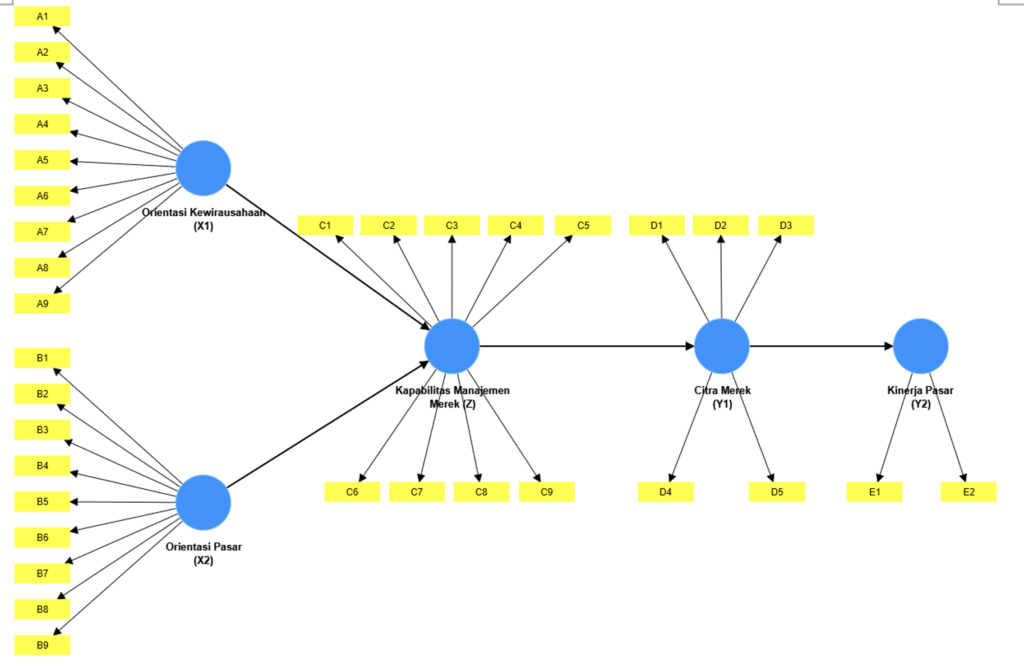
Analisis Faktor Digitalisasi dan Mentalitas Risiko dalam Meningkatkan Kinerja Usaha Mikro melalui Keyakinan Diri (Efikasi Diri)
Proyek ini bertujuan untuk membedah “mesin” penggerak Kinerja Usaha pada Usaha Mikro dan Kecil (UMK) di Jakarta Barat. Ada dua pemicu utama yang diuji: seberapa jauh mereka menggunakan teknologi (Digitalisasi) dan seberapa berani mereka mengambil tantangan (Pengambilan Risiko).
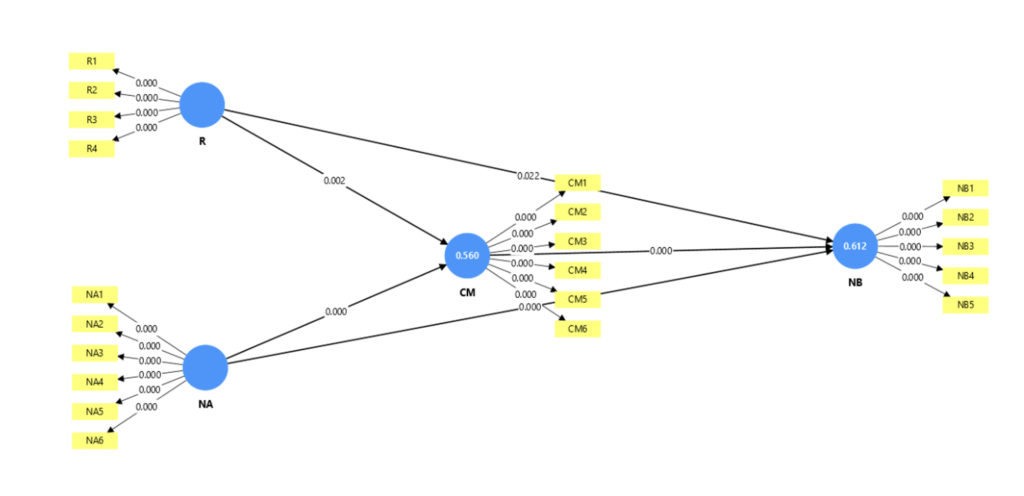
Analisis Faktor Penentu Niat Beli Konsumen: Peran Negara Asal, Resiprositas, dan Citra Merek
Proyek ini bertujuan untuk menguji bagaimana reputasi Negara Asal (Country of Origin), hubungan timbal balik (Resiprositas), dan kekuatan Citra Merek memengaruhi keinginan konsumen untuk membeli sebuah produk. Hasil menunjukkan bahwa semua variabel tersebut memiliki pengaruh positif dan signifikan.
Our Work
Portfolio Showcase for SPSS Project
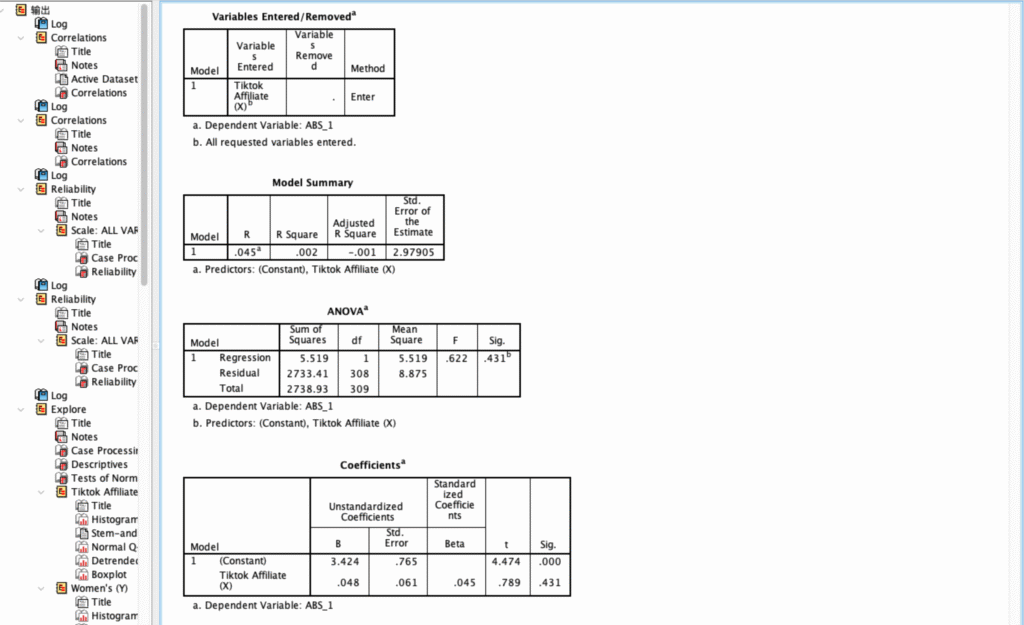
Analisis Efektivitas Program TikTok Affiliate dalam Mempengaruhi Minat Beli Konsumen Wanita
Proyek ini bertujuan untuk mengukur sejauh mana TikTok Affiliate berkontribusi terhadap variabel Women’s. Hasil uji statistik menunjukkan adanya pengaruh positif dan signifikan, di mana setiap penguatan aktivitas TikTok Affiliate akan diikuti oleh peningkatan nilai pada variabel Women’s.
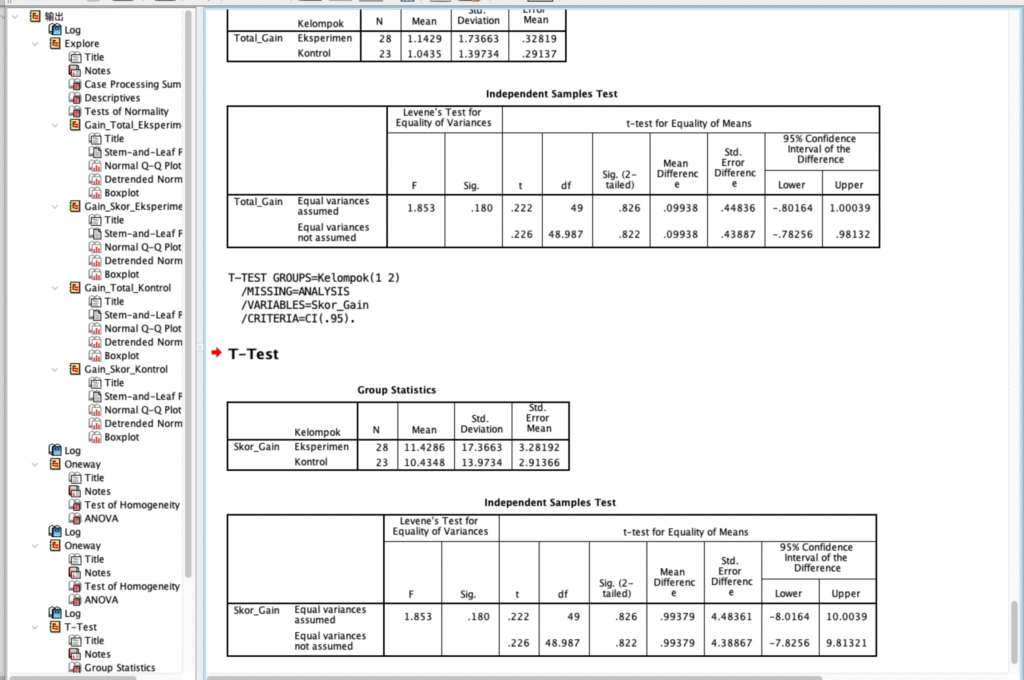
Analisis Efektivitas Perlakuan terhadap Peningkatan Skor (Gain) pada Kelompok Eksperimen dan Kontrol
Proyek ini berfokus pada perbandingan keberhasilan suatu intervensi atau metode baru. Inti dari studi ini adalah mengukur seberapa besar peningkatan (gain) yang terjadi pada subjek yang diberikan perlakuan tertentu (Kelompok Eksperimen) dibandingkan dengan subjek yang tidak diberikan perlakuan tersebut atau menggunakan metode standar (Kelompok Kontrol).
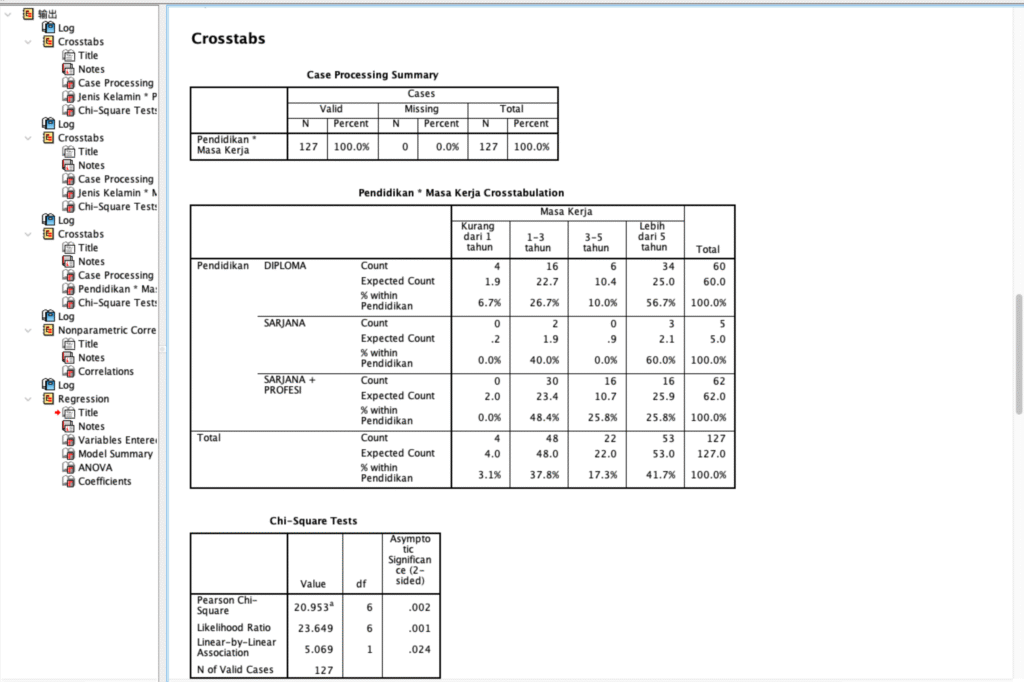
Analisis Faktor Dominan yang Memengaruhi Kepuasan Kerja Karyawan: Tinjauan pada Beban Kerja, Lingkungan, dan Komunikasi
Proyek ini bertujuan untuk mengidentifikasi variabel mana yang paling kuat memengaruhi Kepuasan Kerja. Hasil menunjukkan bahwa faktor eksternal dan relasional, yaitu Lingkungan Kerja dan Manajemen Komunikasi, memiliki dampak positif yang signifikan.
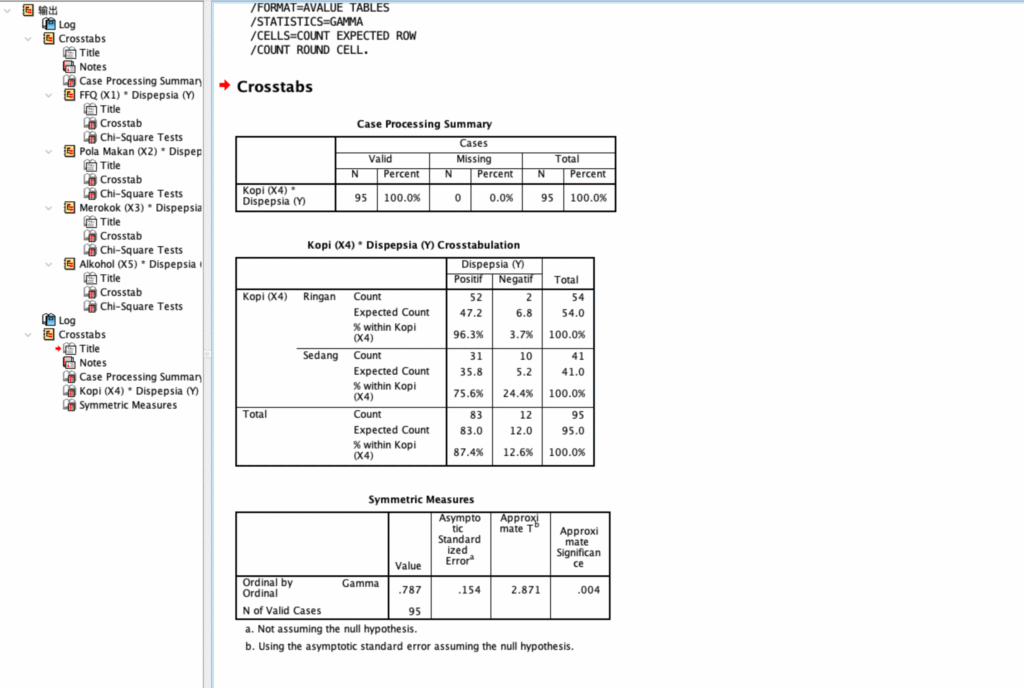
Hubungan Kebiasaan Konsumsi Kopi terhadap Tingkat Keparahan atau Kejadian Dispepsia
Proyek ini bertujuan untuk mengetahui apakah terdapat keterkaitan antara intensitas minum kopi seseorang dengan munculnya gejala dispepsia (nyeri lambung/sakit maag). Fokus utamanya adalah membuktikan secara statistik apakah kebiasaan tersebut menjadi faktor yang sejalan dengan tingkat keluhan pencernaan yang dialami oleh responden dalam kelompok sampel tersebut.
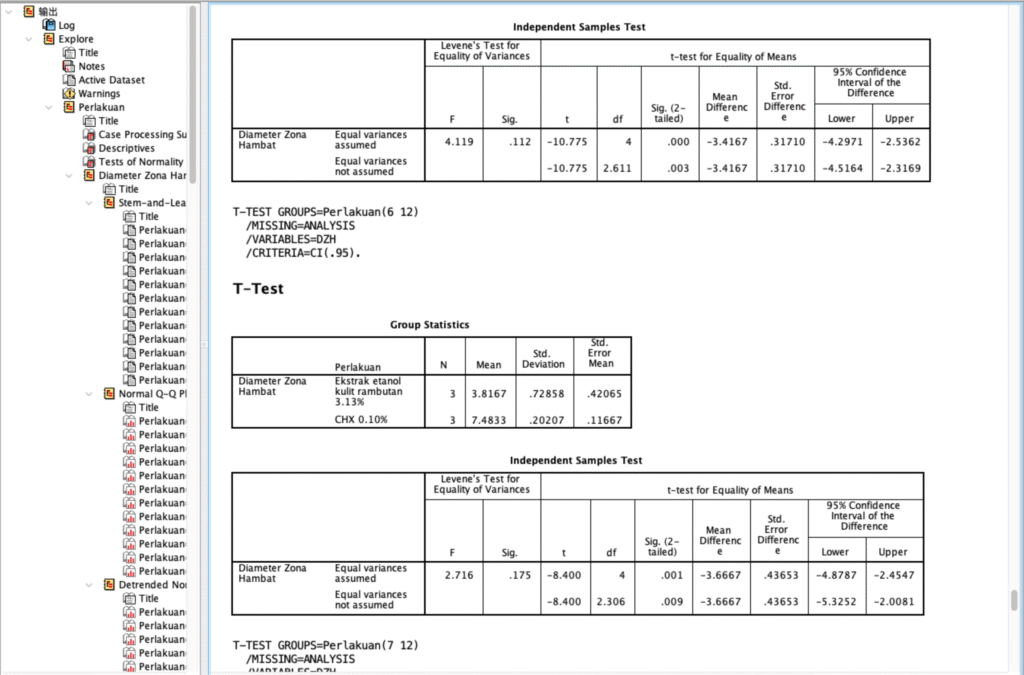
Uji Efektivitas Ekstrak Alami terhadap Daya Hambat Pertumbuhan Bakteri
Proyek ini berfokus pada pengujian kemampuan Ekstrak Etanol Kulit Rambutan dalam menghambat pertumbuhan mikroorganisme dibandingkan dengan bahan kontrol standar (CHX atau Chlorhexidine). Inti dari proyek ini adalah membandingkan berbagai konsentrasi ekstrak untuk melihat seberapa besar Diameter Zona Hambat yang dihasilkan.